Yoshiaki Bando, Kouhei Sekiguchi, Kazuyoshi Yoshii
Abstract: This paper presents a neural speech enhancement method that has a statistical feedback mechanism based on a denoising variational autoencoder (VAE). Deep generative models of speech signals have been combined with unsupervised noise models for enhancing speech robustly regardless of the condition mismatch from the training data. This approach, however, often yields unnatural speech-like noise due to the unsuitable prior distribution on the latent speech representations. To mitigate this problem, we use a denoising VAE whose encoder estimates the latent vectors of clean speech from an input mixture signal. This encoder network is utilized as a prior distribution of the probabilistic generative model of the input mixture, and its condition mismatch is handled in a Bayesian manner. The speech signal is estimated by updating the latent vectors to fit the input mixture while noise is estimated by a nonnegative matrix factorization model. To efficiently train the encoder network, we also propose a multi-task learning of the denoising VAE with the standard mask-based enhancement. The experimental results show that our method outperforms the existing mask-based and generative enhancement methods in unknown conditions.
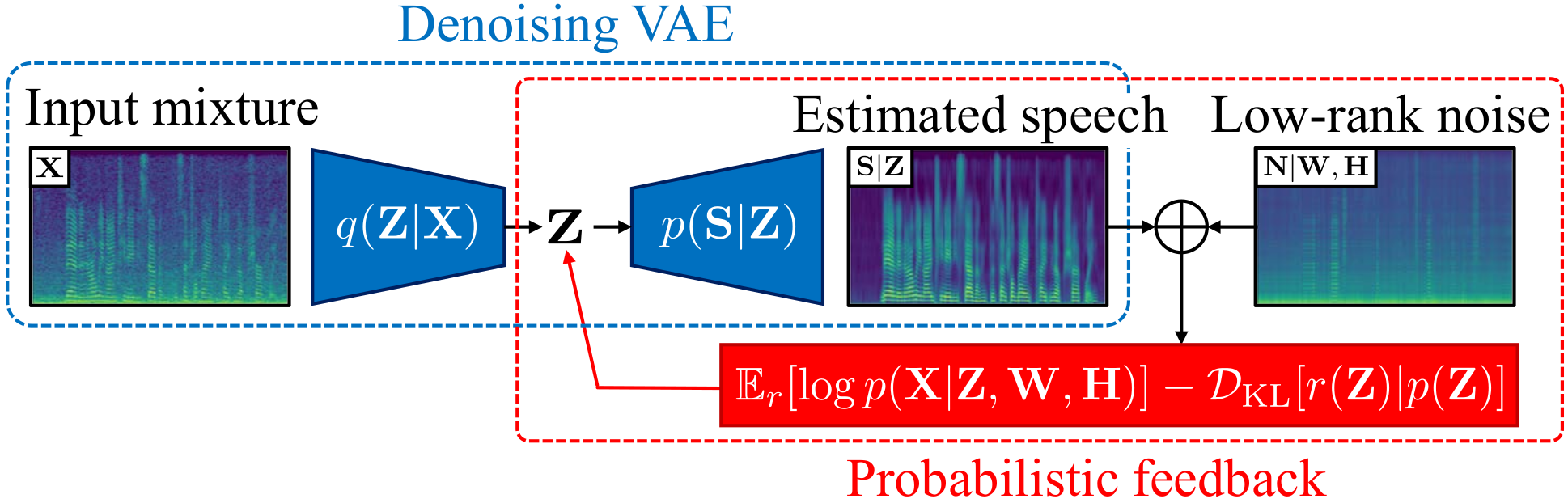
Fig. 1: Overview of our adaptive speech enhancement model.
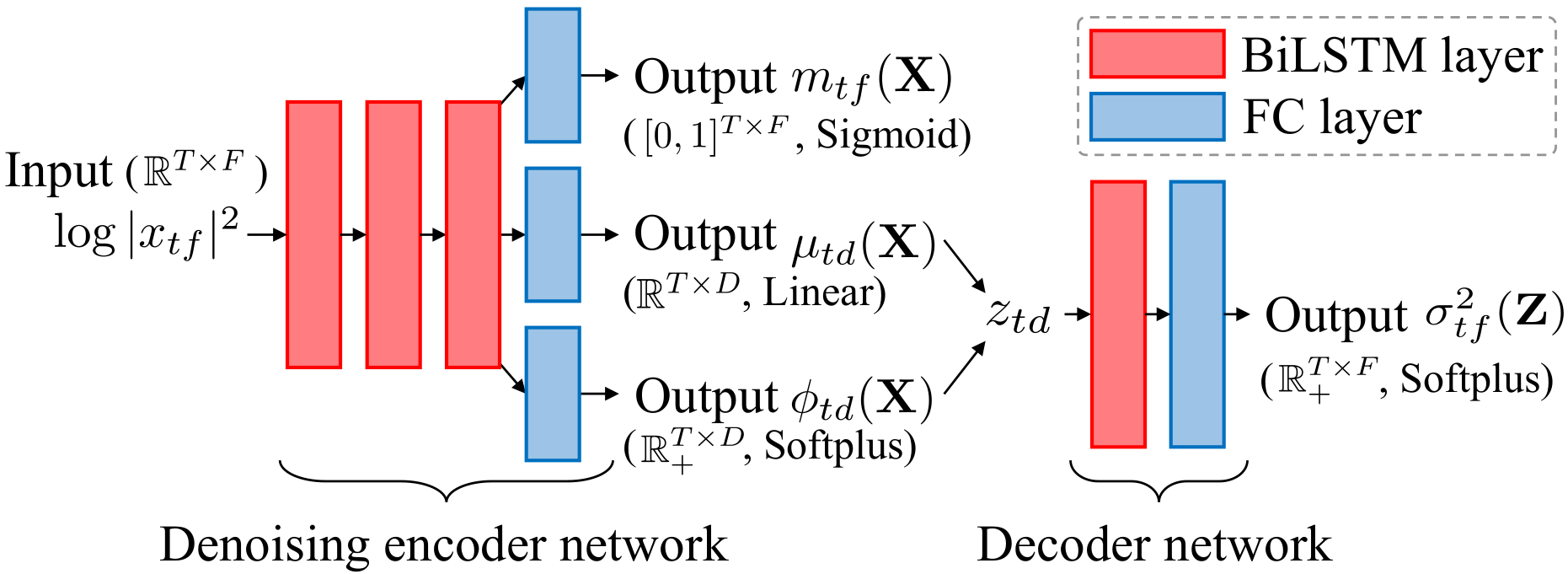
Fig. 2: Network architectures of encoder and decoder.
NOTE: this dataset is known condition for BiLSTM-MSA, BiLSTM-PSA, and DnVAE-NMF.
NOTE: this dataset is unknown condition for BiLSTM-MSA, BiLSTM-PSA, and DnVAE-NMF.